Last week while Kristoffer and Arnaud was in Singapore showcasing our Loco positioning system and Crazyflie at ICRA we initiated moving to a new bigger room here at The Ground. The Ground is a great business collective hosting offices for companies such as Mapilary, Monix, Castle to name a few. It is a very inspirational place to be with a great sharing climate which helps a lot for startups and early phase companies and we are happy to be part of it.
One of the nice things with the new office is that we now can have a dedicated flying area close buy and don’t have to run up and down the basement all the time. Hopefully this will help us speed up development and testing a bit, benefiting not just us, but the whole community :-).
So next time you get an email or forum post written from us you know where it is likely to have been typed.
A couple of weeks ago we played with recording and retracing trajectory directly from the Crazyflie using Loco Positioning System. The result was quite nice and resulted, a first for us, in a fully autonomous Crazyflie, no computer or controller required:
We decided to expand on this experiment for our demo at ICRA. We have modified the retracing code to accepts multiple modes, including running pre-programmed sequence. The plan for the demo is to have Crazyflies that can:
Record and retrace a manual trajectory
Record and replay in a loop a manual trajectory
Play a pre-defined trajectory in a loop
Land automatically when the battery level is low
With this we should be able to demonstrate quite well the capabilities of both the Crazyflie and the Loco Positioning system, and since we do not require a computer in the loop it simplifies a lot running the demo. Of course we keep the possibility to connect the Crazyflie with the Crazyflie client and with ROS while the crazyflie is flying.
Having a completly autonomous Crazyflie is also new to us and it brings its share of problems: how to we choose the working mode and how to we stop the flight if something happens (things tends to happen …).
To solve the former we have made a button deck that adds 2 push-button to the Crazyflie. One means “Start autonomous sequence”. The second means “Record trajectory”. If the recorded trajectory is a loop (if the end point is close to the start point) then the loop is played back as soon as the crazyflie is dropped, otherwise Crazyflie retraces the trajectory and stop.
We solved the later problem by making an autonomous emergency stop button that sends a radio watchdog signal. If the signal stops to be sent or if an emergency stop signal is sent (ie. by pressing the button), the Crazyflie will stop all motors and drop. The button is implemented using a Raspberry pi, a Crazyradio and an Arduino to interface the button:
If you are curious about code, we have created a github repos where we push all code we are making for this demo. As usual, this conference is an opportunity for us to hack new functionalities, though not everything can be done in the master branch. Later some things can be merged, others (like the retrace trajectory recorder/player that looks more like a user app.) will need much more though if we want to merge it in the Crazyflie firmware.
We have not finalized our demos yet but they will include autonomous flight with the Crazyflie and the Loco Positioning system. We also hope to show our brand new optical flow expansion deck that will enable positioning and autonomous flight when on a tight budget. We also plan to show integration with external computers running ROS or our own python library. If we are lucky there might even be a small swarm, even though the space is very limited.
We love to talk to people that are using our products or just interested in our technology, if you are at the conference please drop by and say hi and tell us what you are working on. We will arrive in Singapore on Saturday morning May 27, and if you want to hook up and say hi and have a coffee during the weekend, drop us an email.
Ever since we released the Alpha round of the Loco positioning system we’ve been talking about designing a more generic tag that could be used together with other robotics platforms for local positioning. We did a quick design of a prototype that we tested, but with the workload involved in bringing the LPS out of Early Access, finishing the Z-ranger and lots of other stuff , it’s remained on the shelf. But recently we’ve been getting more and more requests for this kind of hardware, so we thought it might be time to dust off the prototype and try to release it. One of the blockers (except workload) has been that we’re not sure how the tag should look mechanically and how to interface it electrically for it to be as useful as possible for our community. This post is for detailing the current status of the hardware/firmware and to see if we can get some feedback on what our community would like the finished product to look like.
The hardware
To make use of the firmware that’s been developed so far for the Crazyflie and the Loco positioning we aimed at making something similar to what we already have but with another form factor and slightly different requirements. As you might know the Loco positioning node can be configured as a tag, but there’s two drawbacks that we wanted to fix. First of all the Loco positioning node might be a bit big to put on smaller robots. Secondly the Loco positioning node can only measure the distances to the anchors, it doesn’t have an IMU to get attitude of the board and doesn’t have the processing power to run the same algorithms we have on the Crazyflie 2.0.
So for our Loco positioning tag prototype we decided to fix these. The prototype has the same sensors as the Crazyflie 2.0: Gyro, accelerometer, magnetometer and pressure sensor. It also has the same MCU as the Crazyflie 2.0: STM32F405. In addition to this it has the DWM1000 module for the ultra wide-band radio (used for positioning). We’ve also added the interfaces we have on the Crazyflie 2.0: SWD debugging, micro-USB for communication and power as well as a button. Looking at the pictures below you might also notice that we’ve added the Crazyflie 2.0 deck connector. So does this mean you can connect it to the Crazyflie 2.0? No, well not this prototype at least. The reason for adding it was we wanted to be able to use the same expansion decks as for the Crazyflie 2.0. So it’s possible to add the breakout deck for breadboard prototyping or the LED-ring for visual feedback.
So what’s the status of the hardware? Even though it’s the first prototype it’s fully functional and will give you positioning and attitude. What’s left is defining the electrical interfaces and the form-factor of the board so it can easily be attached to what ever you might want to track. The images below shows a side-by-side comparison with the current Loco positioning deck.
Loco positioning tag (on the right) compared to Loco positioning deck (on the left) (FRONT)
Loco positioning tag (on the right) compared to Loco positioning deck (on the left) (BACK)
The firmware/software
Like I wrote above we wanted to reuse as much of the firmware and software as possible. So the firmware running on the prototype is just a scaled down version of the Crazyflie 2.0 firmware. As you might have noticed the prototype looks a lot like the Crazyflie 2.0, except that it’s not a quadcopter and doesn’t have the nRF51 radio. So by “scaled down” I mean we’ve removed the motor and radio drivers, that’s about it. So how do you communicate with it? Well you can use one of the protocol available on the deck connector: SPI, I2C or UART. But the currently implemented way is using USB. Since it’s basically a Crazyflie you can use our client and python libraries to set parameters and log data values from it.
Conclusion
The current prototype is basically a USB dongle where you get position and attitude. It could easily be connected via USB to a Raspberry Pi, Beaglebone or any other SoC based platform or a computer. You can also interface it from an Arduino using the peripherals on the deck connector. The firmware is working and using the python library (or any other of our community supported libraries) you can easily get the position and attitude of the board. But to be able to take the next step and make something our community could make the most of we would love some feedback on the prototype. What kind of electrical interfaces and form-factor would you like?
We are happy to announce that we have released new versions of the Crazyflie Firmware and the Crazyflie client, both are now in version 2017.4. The main feature of the release is support for the new Z-Ranger deck.
To support the Z-Ranger, a new flight mode has been added to both the firmware and the client: the Height-hold mode. This mode allows to fly with the Z-ranger deck at a fixed height above the floor.
There are also a number of other improvements and bug fixes in the releases, mainly related to the Loco Positioning system and autonomous flight.
On the client side, this new release is also a come-back of the windows build. It means that it is now easier to get started and fly your Crazyflie directly from Windows as you can install it as a native app. We really want to build the client for Mac OS too but have met some problems. If anyone has experience in building pyqt apps for mac OS, with your help we might be able to have a mac build for the next client version ;-).
Seeedstudio has been our main distributor and manufacturer since we started and they have also acted as our main sales channel. A couple of years ago we started to discuss setting up our own E-shop and finally last year we decided to try our own wings. We wanted to start small and treated the E-shop as an experiment, since we are newbies at e-commerce and are learning as we are going. The E-shop has been up and running for almost 10 month now without really being official, but now we have decided to go all in!
We have definitely experienced different ups and downs this last 10 months but overall it has been a positive experience. Handling the logistics and balancing stock between different warehouses have been a challenge but in return we can now communicate with and support our customers in a better way. We have been able to release hardware early to our community through our Early access program, which has been very exciting and also given us a lot of useful feedback. We have also been able to continuously improve the overall user experience by for instance creating bundles and better information architecture.
Check our store out at https://store.bitcraze.io/ and let us know what you think! We are always trying to improve and all feedback is welcome.
Remember we still have all our great local distributors, if you prefer to buy locally please check out our distributor list.
Early on when we started to work on the Loco Positioning system, we came up with an idea of a Crazyflie autonomously flying into a light box, positioning it self for a few product pictures and then flying out again. The positioning system is now pretty mature and close to leave Early Access and this Friday we finally got around to do it. In this blog post we will share what we did and it also doubles as a brief howto on how to set up the system and fly a simple autonomous sequence.
We used a Crazyflie with a Loco Positioning Deck and eight Loco Positioning Anchors in our setup. Six anchors would have been fine too, but we happened to have eight in our flight lab.
When working with the Loco Positioning system the first step is always to make sure the anchors are set up correctly. We had an experimental version of the anchor firmware so we started out by pulling down the latest stock version of the source code and compiled it into a .dfu file. After that we fired up the brand new lps-tool that is used to flash firmware and configure the anchors. The anchors must be connected with a USB cable to the computer but the lps-tool reduces the flashing and configuration into a few clicks. When all anchors were updated we were ready for the next step.
The positions of the anchors are stored in the anchors them selves and the position is transmitted to the Crazyflie as a part of the ultra wide band messages used for measuring the ranges to the anchors. This way, the Crazyflie gets both anchor positions and ranges in the same process and has all the information needed to calculate its position. The second step is thus to store the positions in the anchors. In our “flight lab” we have fixed mounts for the anchors with known positions, so we could skip measuring the physical positions of the anchors.
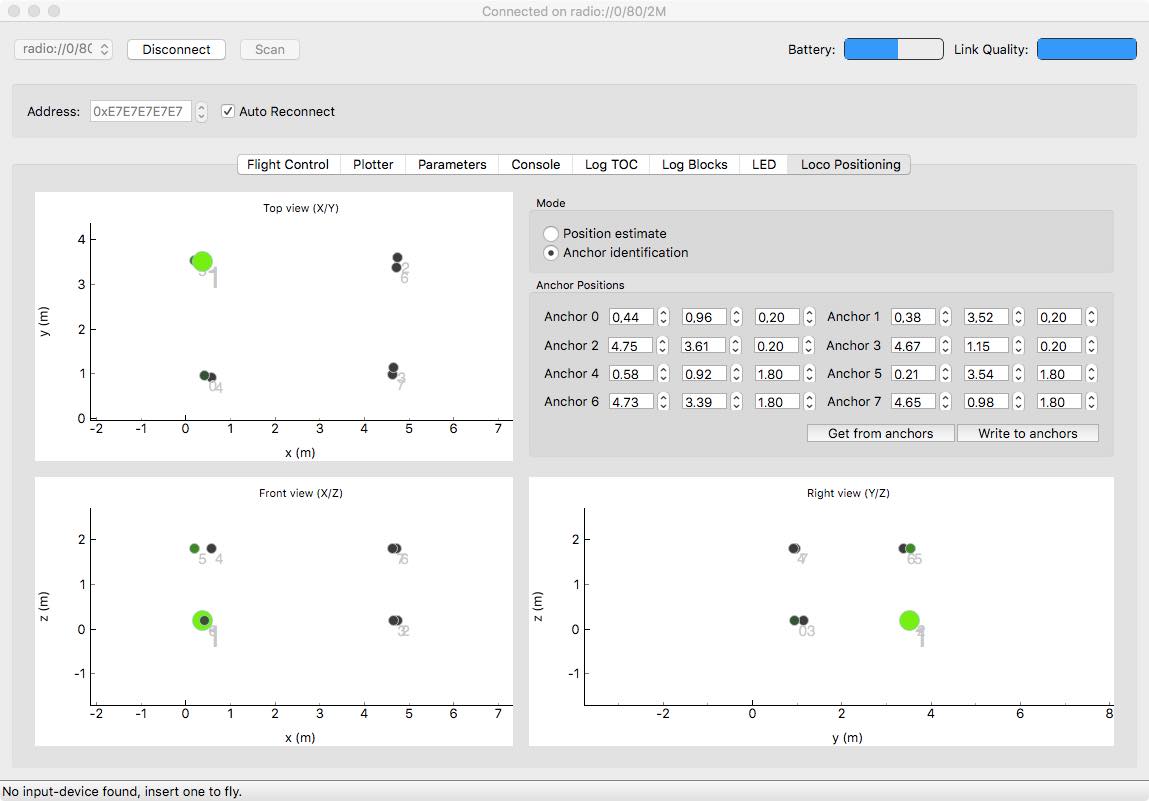
We are working on making it possible to remotely configure the anchors to reduce the need to physically connect to them, and the position can now be set from the Crazyflie Client. We simply opened the “Loco Positioning” tab in the client, connected to a Crazyflie (with a Loco Positioning deck mounted), entered the anchor positions and hit the “Write to anchors” button. A few seconds later the anchor positions in the graphs were updated to indicate that the positions have been written to the anchors and then subsequently sent back through the ultra wide band messages to the Crazyflie.
Step three is to verify that the system is working as expected. First thing is to check that we did not mix the anchors up when configuring or placing them. In the “Loco Position” tab in the client, click the “Anchor Identification” button. In this mode anchors are lit up in the graphs when the Crazyflie gets close to them in the physical world. We went from anchor to anchor with the Crazyflie and checked that the correct anchor lit up on the screen. When confident that all was good we changed to “Position estimate” mode and verified that the estimated position matches the physical position of the Crazyflie. We have found that it can be very hard to understand, for instance that two anchors have been mixed up, by looking at the estimated position and that the “Anchor Identification” step simplifies the setup.
At this point we had a fully functioning Loco Positioning system ready for autonomous flight!
Now it was time to script a sequence. The easiest way to script a sequence is to start from the autonomousSequence.py example. Our intern Alfred took over at this point, he updated the uri to the correct settings and crafted a sequence to take off, fly into the light box, wait a while and then fly back out for a stylish landing in his hand!
Now we were ready for the actual photo shoot and Björn came down with the camera to shoot the product pictures. We hope you enjoy the results!
Lately the Crazyflie has been used more and more as a demonstration and reference platform by a number of sensor manufacturers, including Bosch Sensortec. The possibility to add expansion decks to the platform and that the project is open source makes the Crazyflie very suitable to test and demonstrate new sensors in real time. For us this is a further confirmation of the strengths of working with open source and it enables us to provide the community with new and cool expansion decks as early as possible.
We are glad that the industry sees the value in our open source project and is interested in collaborating with us. This will enable us to continue to evolve this and other exiting new hardware project in the future. If you and your company is interested in a collaboration, please read more on our “Used by the industry” section.
Bitcraze is not organized as most other companies, we are self organizing, strong believers in continuous improvement and are minimizing planing to be as agile and flexible as possible. We have written a few blog posts about this earlier. One result of this philosophy is that we don’t have a long term plan or road map to share, for instance of when a particular product will be released, but never the less we will tell you a bit about what we think lies ahead of us for the Loco Positioning system.
Our goal for the coming weeks is to finalize the first version of the positioning system, that is to leave the Early Access phase. The capabilities of the first release will be to autonomously fly one Crazyflie using two way ranging. The more advanced features such as TDoA will be considered experimental and requires compile time flags to be enabled.
We feel that the performance of the system is reaching levels that we think are good enough for many use cases, what is still lacking is ease of use. To fix that we are focusing on simplifying installation and configuration of the system by adding a few new tools.
We have found that one problem area is to install the system and get the anchor positions right. If the positions are not correct the estimated position of the Crazyflie will of course be wrong and it can be hard to understand what the cause of the problem is. To solve this we have added a new tab in the PC client (the LPS tab) that allows the user to see and configure the anchor positions as well as see the estimated position of the Crazyflie. There is also a mode in the client that is used to identify anchors by moving the Crazyflie around in the room, when close to an anchor that anchor lights up in the client to verify the setup.
Loco Positioning Tab
The anchor positions have up till now been stored in the Crazyflie or the client (ROS or python script), which is not optimal as data in the firmware or client becomes tightly coupled to the physical layout of the positioning system. If we move an anchor we either have to rebuild the Crazyflie firmware or have to transfer position data from the client to the Crazyflie before we can estimate the position. The solution is to move the anchor position into the anchor it self and send it as a part of the ultra wide band communication to the Crazyflie when ranging.
In the current Loco Positioning Node firmware, configuration changes and firmware updates are a bit cumbersome as it requires a few different external software packages. Further more different tools are needed depending on the OS of the host. To simplify this process we are working on a LPS-tool that will enable the user to configure and update the nodes using a GUI with clear feedback on the progress. The tool is written in python and the intention is that it will work on all our supported platforms.
We hope these improvements will lead to a positioning system that is easy to use and will enable all you people out there to do awesome stuff! As always, feedback is welcome.
We have spent most of our time working on the two way ranging in the Loco Positioning system lately, mainly on features that are not directly related to the actual ranging but such as making it easier to configure and upgrade the anchors. As a result we have not exercised the TDoA mode in a while, so on our Fun Friday we wanted to play a bit with that and try to fly a small swarm with some sort of coordinated autonomous flight.
Setup
We have a Loco Positioning system set up in the basement, we call it the flight lab to make it sound more fancy! The setup has been 6 anchors with three anchors in the ceiling and three on the floor, configured as triangles pointing in opposite directions. When using two way ranging that is fine as the positioning works pretty well outside the volume defined by the anchors. For TDoA on the other hand, the accuracy of the estimated position degrades rapidly when you go outside the convex hull. We decided to add two more anchors (to a total of eight) and arrange them as the corners of a box. A few hours and mounting/cabling later we were ready to try it out.
We modified the swarmSequence script to suite my (limited) space and set it up to fly four Crazyflies in a square, moving them to the next corner of the square every 5 seconds. Next problem was to find 4 working Crazyflies and Loco Positioning decks. We have a few Crazyflies lying around but a fair number of them have been modified in one way or another but finally we had the hardware we needed and could run the script. After a couple of failed tries (out of battery and such) we shot this video
Lessons learned
So what did we learn from this exercise? Adding two more anchors and changing anchor positions improved the positioning significantly. We have seen earlier that TDoA is less accurate than two way ranging, but better anchor positions reduces the problem. We could also fly the swarm using our example python script (not using ROS) without too much work and trouble, even though the TDoA mode still is very experimental.
In this flight we used the stock controller and just moved the set point to the next desired position for each copter. We are really looking forward to try out the improved controller and trajectory planning that we showed at Fosdem in combination with the TDoA mode, we think it will improve the performance a lot!